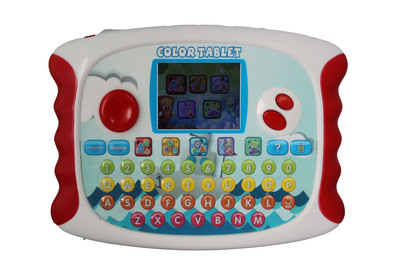
小Q鴨兒童早教玩具 寓教于樂的學習伙伴

在當今注重兒童早期發(fā)展的時代,一款優(yōu)秀的早教玩具不僅能帶來歡樂,更能成為孩子成長路上的良師益友。小Q鴨兒童早教玩具,特別是其系列中的兒童學習機,憑借其科學的設計、豐富的功能與親民的價格,贏得了眾多家長的青睞。本文將帶您深入了解小Q鴨早教玩具的生產(chǎn)源頭、產(chǎn)品特性以及市場定價。
一、 匠心制造:可靠的小Q鴨生產(chǎn)廠家
小Q鴨品牌隸屬于一家專注于兒童益智產(chǎn)品研發(fā)與生產(chǎn)的現(xiàn)代化企業(yè)。該生產(chǎn)廠家通常具備以下核心優(yōu)勢:
- 安全至上:嚴格遵循國際及國內兒童玩具安全標準(如3C認證),采用環(huán)保無毒、耐用的ABS材質,確保產(chǎn)品安全可靠,讓家長放心。
- 教育為本:與幼教專家合作,根據(jù)兒童不同成長階段(如0-3歲、3-6歲)的認知發(fā)展特點,設計開發(fā)內容。學習機內置的課程涵蓋語言、數(shù)學、音樂、邏輯思維等多個領域。
- 技術創(chuàng)新:融入智能語音互動、觸摸感應、多彩燈光等科技元素,提升玩具的趣味性和互動性,激發(fā)孩子的探索欲和學習興趣。
- 嚴格質檢:從原料采購到成品出廠,建立完善的質量管控體系,確保每一件到達消費者手中的產(chǎn)品都品質如一。
了解廠家的實力,是信任產(chǎn)品品質的第一步。正規(guī)的廠家信息通常可通過產(chǎn)品包裝、官方網(wǎng)站或授權銷售渠道查詢。
二、 核心產(chǎn)品聚焦:小Q鴨兒童學習機的魅力
作為小Q鴨早教玩具系列中的明星產(chǎn)品,兒童學習機集多種功能于一體:
- 多元學習內容:包含中英文雙語啟蒙、兒歌故事、趣味算術、生活常識等,通過卡通界面和悅耳音效生動呈現(xiàn)。
- 互動體驗:設計有問答模式、跟讀功能、小測驗等,鼓勵孩子主動參與,在游戲中鞏固知識。
- 人性化設計:機身圓潤無棱角,音量可調且設有護眼模式,充分考慮兒童的使用安全與健康。
- 便攜耐用:尺寸適中,便于攜帶,電池續(xù)航能力強,適合家庭及外出使用。
這類學習機旨在將“被動玩耍”轉變?yōu)椤爸鲃訉W習”,為孩子營造一個輕松愉快的早期教育環(huán)境。
三、 市場價格解析:小Q鴨兒童早教玩具的價格區(qū)間
小Q鴨早教玩具的價格因其產(chǎn)品類型、功能復雜度、配置高低而有所不同,總體定位偏向高性價比。
- 基礎款早教玩具/簡易學習機:價格通常在幾十元到一百多元人民幣。功能相對集中,適合低幼齡兒童進行基礎認知啟蒙。
- 多功能進階版學習機:價格區(qū)間多在一百多元至三百元人民幣。這類產(chǎn)品功能更為豐富,互動性更強,可能包含屏幕(非電子視頻屏)、更多學習卡片或模塊,適合學前兒童。
- 影響價格的因素:主要包括內容資源的版權與豐富度、硬件材質與工藝、智能技術應用程度以及品牌渠道等。節(jié)假日或電商平臺促銷期間,通常能以更優(yōu)惠的價格購入。
建議消費者通過品牌官方旗艦店、授權經(jīng)銷商或主流電商平臺購買,以確保產(chǎn)品正品和完善的售后服務,同時可以清晰對比不同型號的具體配置與價格。
小Q鴨兒童早教玩具,尤其是其兒童學習機,通過可靠的生產(chǎn)保障、科學的早教內容和親民的市場定價,成功地將教育理念融入趣味玩具之中。在為孩子挑選早教產(chǎn)品時,小Q鴨無疑是一個值得考慮的優(yōu)質選擇,它不僅能陪伴孩子度過歡樂時光,更能潛移默化地啟迪智慧,助力他們邁出探索世界的第一步。
如若轉載,請注明出處:http://www.ztqbj.cn/product/18.html
更新時間:2026-06-19 23:05:36