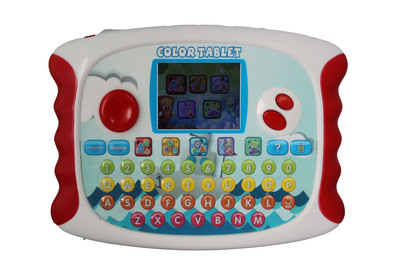
多功能兒童學習機 從早教到初中同步的智能學習伙伴

在當下教育信息化與家庭教育需求日益增長的背景下,集點讀、同步輔導與多學科學習于一體的兒童學習機,已成為許多家庭輔助孩子學習的重要工具。一款宣稱覆蓋“幼兒童小學生初中同步九門功課”的學習機平板電腦,究竟能提供怎樣的學習體驗?它是否真能成為孩子從早教到初中階段的“家庭教師”?本文將為您解析其核心功能與適用場景。
一、 產品定位:覆蓋廣泛學齡段的綜合性學習工具
這類學習機通常瞄準3-15歲左右的孩子,即從學齡前早教階段延伸到整個九年義務教育時期。其核心賣點在于“同步”,即內置了與全國各地主流教材版本相匹配的語文、數學、英語等九門課程的學習資源。這意味著,理論上孩子從幼兒園的啟蒙認知,到小學的扎實基礎,再到初中的知識深化,都可以在這一臺設備上找到對應的學習內容。它試圖打造一個“一站式”的學習平臺,減少家長為孩子不同階段尋找不同學習工具或資源的麻煩。
二、 核心功能亮點解析
- 智能點讀與早教啟蒙: 對于幼兒和低齡兒童,點讀功能是關鍵。通過觸屏或配備的點讀筆,孩子可以點擊課本、繪本上的文字或圖片,設備即時發出標準的發音或解釋。這極大地激發了幼兒的學習興趣,在無壓力的互動中認字、學拼音、接觸基礎英語,是語言啟蒙的有效方式。
- 九門功課同步輔導: 針對小學和初中生,學習機內置了與學校課程進度同步的視頻講解、習題庫、知識梳理和測試卷。學生可以用它來預習新課、復習鞏固、查漏補缺。特別是對于課堂上未能完全消化的知識點,可以反復觀看名師講解視頻,相當于擁有了一個隨時可請教的“家教”。
- 專注學習與家長管控: 與普通平板電腦最大的區別在于,優質的學習機通常采用封閉或高度定制的系統,屏蔽了游戲、無關網頁和社交軟件,營造一個純凈的學習環境。家長可以通過手機APP遠程管理設備使用時長、查看學習報告,了解孩子的學習進度和專注情況,有效避免孩子沉迷娛樂。
- AI技術與個性化學習: 部分高端型號會引入人工智能技術,如AI指學、作文批改、口語測評等。AI能夠識別孩子指讀的課本內容,提供講解;對英語跟讀進行發音打分和糾正;甚至能模擬考試場景,生成個性化的薄弱環節練習報告,實現“因材施教”的雛形。
三、 優勢與潛在考量
優勢:
資源整合,方便高效: 省去四處尋找學習資料的精力,權威同步內容有保障。
互動性強,提升興趣: 點讀、動畫、闖關練習等形式比傳統書本更吸引孩子。
彌補輔導空缺: 對于家長輔導精力或能力有限的家庭,是很好的補充。
培養自主學習習慣: 在合理引導下,有助于孩子養成自己查找資料、解決問題的習慣。
潛在考量與建議:
屏幕使用與健康: 需嚴格控制單次使用時間,注意使用姿勢和環境光線,保護視力。建議優先選擇有護眼模式、低藍光認證的屏幕。
“工具”而非“替代”: 學習機是輔助工具,不能完全替代教師的課堂教學、家長的親子陪伴以及孩子線下真實的閱讀、實踐和社交。它應作為學習體系的組成部分,而非核心。
內容質量與更新: 不同品牌、型號的學習機,其內置資源的權威性、更新及時性、與本地教材的匹配度可能存在差異。選購前需仔細核實。
年齡匹配度: 雖然宣傳覆蓋全學段,但具體到某一型號,其界面設計、內容深度可能更側重某個階段(如小學)。家長應根據孩子當前的主要需求選擇。
四、
一款功能全面的兒童學習機平板,確實有潛力成為孩子成長路上的得力助手,尤其在提供同步輔導資源、營造專注學習環境和進行趣味啟蒙方面優勢明顯。其最終效果如何,很大程度上取決于產品的實際內容質量、家長的正確引導以及與學校教育的配合。在將其引入家庭教育之前,明確其“輔助工具”的定位,建立合理的使用規則,并持續關注孩子的學習狀態和身心健康,才是讓科技產品真正賦能孩子學習與成長的關鍵。
如若轉載,請注明出處:http://www.ztqbj.cn/product/16.html
更新時間:2026-06-19 07:42:15